정당성
이상 탐지란?
- 정상검체와 비정상검체를 구별하는 문제
분류
학습 중 비정상 샘플 사용 여부 및 표시 여부에 따른 분류.
1. 지도 학습 기반 이상 탐지
- 주어진 학습 데이터 세트에 정상 및 비정상 샘플 데이터와 레이블이 모두 있는 경우.
- 높은 정확도가 필요할 때 주로 사용
- 산업현장에서 이상시료의 발생빈도가 현저히 낮기 때문에 심각한 클래스 불균형 문제
- 데이터 확장, 손실 함수 재설계, 배치 샘플링 등의 기법 적용
2. 반지도 학습 기반 이상 탐지(개별 수업)
- 클래스 불균형이 심한 경우 일반 샘플로만 학습
- 정상 샘플을 중심으로 판별 경계를 설정하고 경계를 최대한 좁혀 경계 외부의 모든 샘플을 비정상으로 간주합니다.
- One-Class SVM, Deep SVDD, Energy-based, Deep Autoencoding Gaussian Mixture Model, GAN, Self-Supervised Learning
3. 비지도 학습 기반 이상 탐지
- 대부분의 데이터가 정상 샘플이라고 가정하여 레이블 없이 훈련하는 방법론
- PCA와 Autoencoder를 이용한 차원축소 및 복원 과정을 통한 이상시료 검출
- 다소 불안정한 정확도
이상검체의 정의에 따른 분류
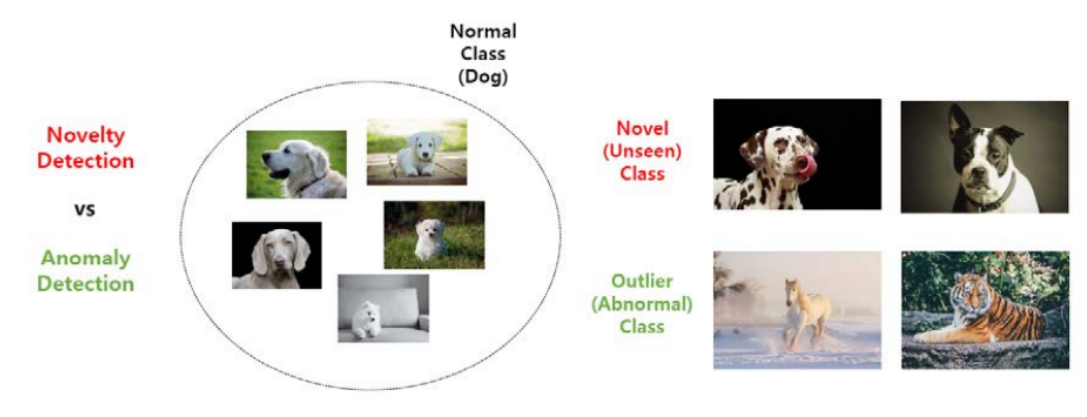
1. 참신함 감지
- 기존 데이터셋에 존재하지 않는 새로운 개(Novel Specimen, Invisible Specimen)를 찾기 위한 방법론
2. 이상값 감지
- 새로운 예가 나오면 개가 아닌 호랑이, 말, 운동화, 비행기 등 개와 상관없는 예가 등장한다.
정상 샘플의 클래스 수에 따른 분류(OOD Detection)
- 정상/비정상 대신 분포 내/분포 외부 표본이라는 문구를 사용하십시오.
- 분포 내 데이터셋으로 네트워크를 훈련시킨 후 테스트 단계에서 비정상 샘플을 찾는 문제
머신러닝 기반 이상 탐지
분류 기반 이상 탐지 기법
- 분류기를 특징 공간에서 훈련할 수 있다고 가정합니다.
- 레이블 수에 따른 단일 클래스 또는 다중 클래스 데이터 학습
- 클래스와 일치하지 않는 개체는 이상값으로 처리됩니다.
- Autoencoders, Bayesian Networks, Support Vector Machines, Decision Rule Bases 등
1. 오토인코더
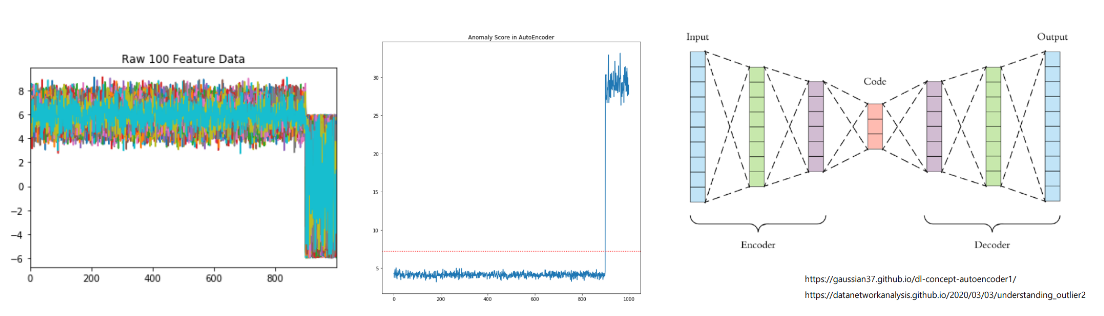
- 비지도 학습 기반 모델
- 하나 이상의 숨겨진 레이어로 구성된 인코더에 의한 입력 데이터의 압축(차원 축소).
- 디코더를 사용하여 객체 재구성(생성 모델)
- 재구성 시 발생하는 재구성 오류가 클수록 이상(anomaly score)으로 평가될 가능성이 높습니다.
2. 베이지안 네트워크 기반
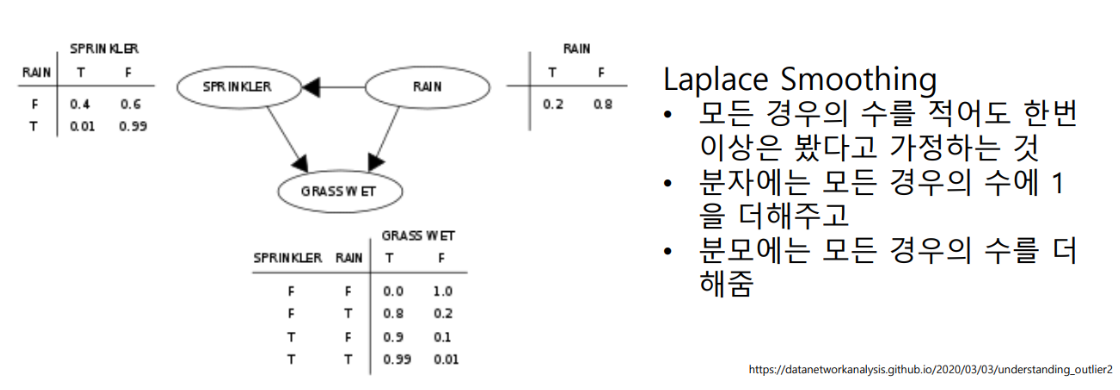
- 다중 클래스 문제에 사용
- 순진한 베이지안 네트워크는 테스트 데이터에서 관측치의 각 정규 클래스 및 비정상 클래스에 대한 사후 확률을 추정하고 확률이 가장 높은 클래스에 할당합니다.
- 각 클래스의 사전 확률과 조건부 확률은 훈련 데이터를 사용하여 추정해야 합니다.
- 확률이 0인 경우 라플라시안 스무딩은 0 대신 1 또는 이에 상응하는 양수 값을 반환합니다.
3. 서포트 벡터 머신 기반
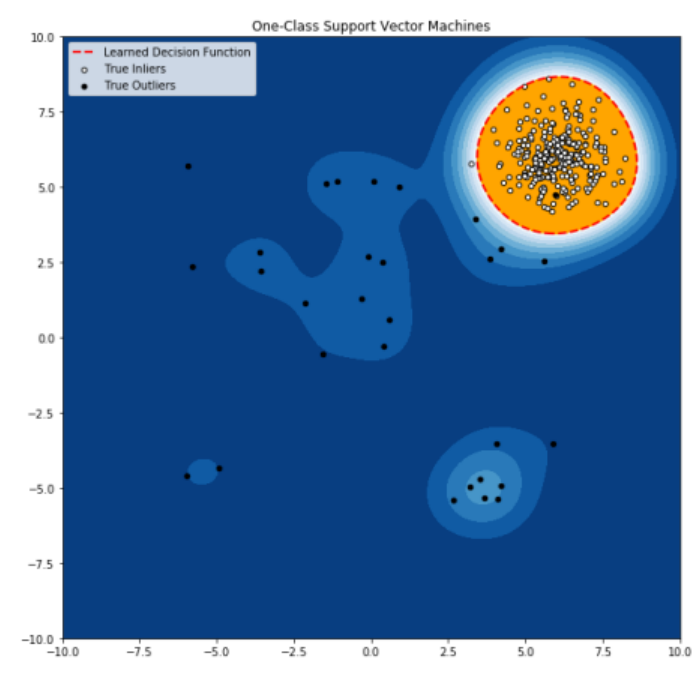
- 단일 클래스 문제에 사용
- 학습 데이터가 포함된 지역 알아보기
- 우리는 결정 경계에만 집중하고 경계 안팎의 분포에는 관심이 없습니다.
- RBF(Radial Basis Function)와 같은 커널 함수는 도메인 분류가 복잡해질 때 가끔 사용됩니다.
- 사용할 커널을 결정해야 합니다.
4. 결정 규칙 기반
- 정상적인 데이터를 평가하고 어떤 규칙도 따르지 않는 관찰을 비정상으로 처리하기 위한 학습 규칙
- 다중 클래스 및 단일 클래스 모두 적용 가능
- 의사 결정 트리와 같은 의사 결정 규칙 학습 알고리즘을 사용하여 훈련 데이터에 대한 규칙을 학습합니다.
NN 기반 이상 탐지 기법
- 정상값이 일부 이웃에 밀집되어 있고 이상치가 각 이웃에서 멀리 떨어져 있다고 가정
- 두 엔터티 간의 거리 개념을 정의해야 합니다.
- 연속 변수: Euclidean, Manhattan, Minkowski, 표준화, Mahalanobis 거리
- 범주형 변수: 단순 일치도 계수(Jacquard Distance)
- 다변량 데이터: 각 변수에 대한 거리 결합
- 비지도 또는 준지도 학습 기반
- 이것이 당신이 이상적인 점수를 얻는 방법입니다
- k번째로 가장 가까운 물체까지의 거리 사용(K-NN 기준)
- 상대 밀도 사용(상대 밀도 기준)
1. K-NN 기반
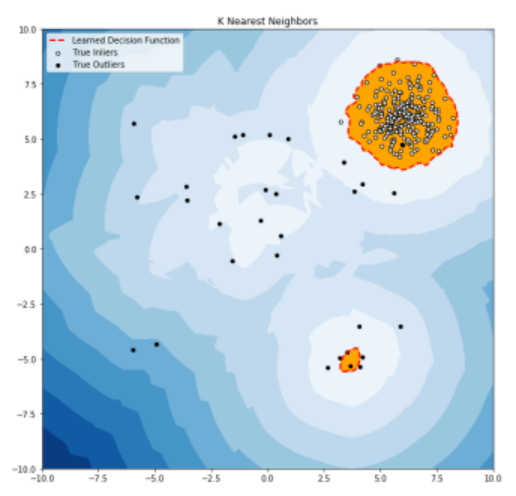
- 이상 점수를 k-가장 가까운 개체까지의 거리로 정의하려면
- 이상 점수의 임계값 설정
- 이상 점수별로 정렬하여 이상 점수가 가장 큰 m 항목을 이상값으로 표시하는 방법도 있습니다.
- 비연속 컴퓨팅을 위한 다른 거리 척도 소개: k개의 가장 가까운 물체까지의 거리의 합, 물체로부터 주어진 거리 내에 있는 물체의 수를 세는 방법, 데이터를 클러스터링하고 k-가장 가까운 물체를 찾는 방법 클러스터 이웃과의 거리, 최소/최대 거리 값을 사용하여 k개의 가장 특이한 개체를 포함하지 않는 클러스터를 제거하고 나머지에서 이상값만 찾습니다.
2. 비중 기준
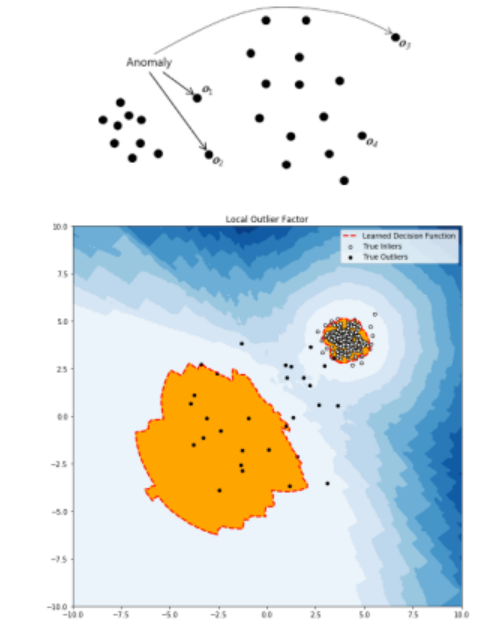
- 각 관측값 부근의 밀도를 추정하고, 그 부근의 밀도가 낮은 관측값을 이상값으로 판단합니다.
- 면적에 따라 밀도가 달라지는 경우 취약 -> 이를 해결하기 위해 국지적 상대밀도 비교 LOF(로컬 이상치 요인) 기술 등장
- 가장 가까운 k 포인트의 로컬 밀도의 평균은 자체 로컬 밀도의 비율로 정의됩니다.
- 고밀도 클러스터에 가까운 경우에도 이상값을 감지합니다.
- 판단 기준은 도메인 지식을 사용하여 한계를 결정해야 합니다.
클러스터링 기반 이상 탐지 기법
- 비지도 학습 방법
- 세 가지 가정
- 정상 값은 하나 이상의 클러스터로 클러스터링되며 이상 값은 클러스터에 속하지 않습니다.
- 군집의 가장 가까운 중심까지의 거리가 작으면 정상값, 멀면 이상값이다.
- 정상 값은 크거나 밀집된 클러스터에 속하고 이상 값은 작거나 희박한 클러스터에 속합니다.
- 이상값이 클러스터를 형성할 때 취약함
- 많은 군집화 알고리즘이 모든 관측치의 군집을 나타내기 때문에 이상값은 큰 군집에 속하고 정상 값으로 판단될 수 있습니다.
- NN 기반 이상 탐지 기법과 유사하게 거리 계산 필요
- 클러스터 기반 이상 탐지 기술은 각 관측치가 속한 클러스터 측면에서 각 관측치를 평가하는 반면, NN 기반 이상 탐지 기술은 각 관측치를 가까운 로컬 이웃과 비교하여 분석합니다.
가정 1
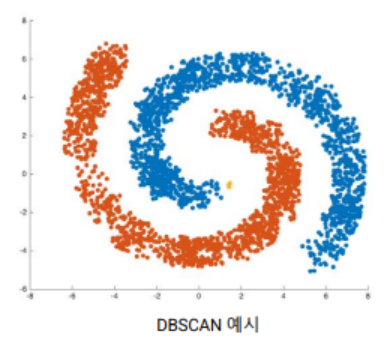
정상 값은 하나 이상의 클러스터로 클러스터링되며 이상 값은 클러스터에 속하지 않습니다.
- 모든 관찰을 클러스터링할 필요가 없는 DBSCAN, ROCK 및 SNN 클러스터링 알고리즘을 사용합니다.
- 데이터에서 클러스터를 찾아 제거하고 나머지는 이상값으로 처리합니다.
- 주요 목적이 클러스터를 찾는 것이므로 이상 탐지에 최적화되어 있지 않습니다.
가정 2
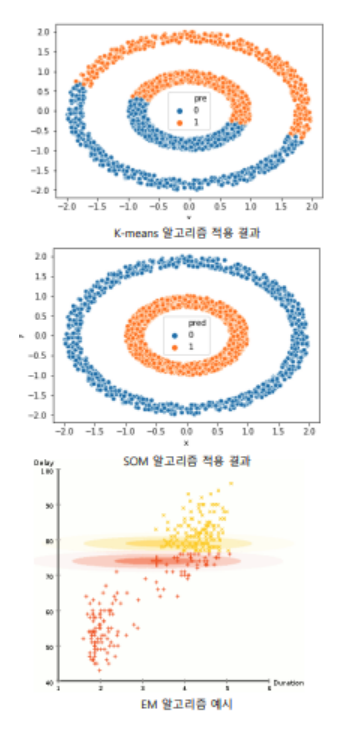
군집의 가장 가까운 중심까지의 거리가 작으면 정상값, 멀면 이상값이다.
- 클러스터링을 수행하고 이상 점수를 관찰과 관찰을 포함하는 클러스터의 중심 사이의 거리로 정의합니다.
- SOM, k-평균 클러스터링, EM 알고리즘
- 학습 데이터를 클러스터링하고 테스트 데이터를 클러스터와 비교하여 아웃라이어 점수를 얻는 준지도 학습 방법일 수 있습니다.
- 이상값이 클러스터링되면 성능이 저하됩니다.
가정 3
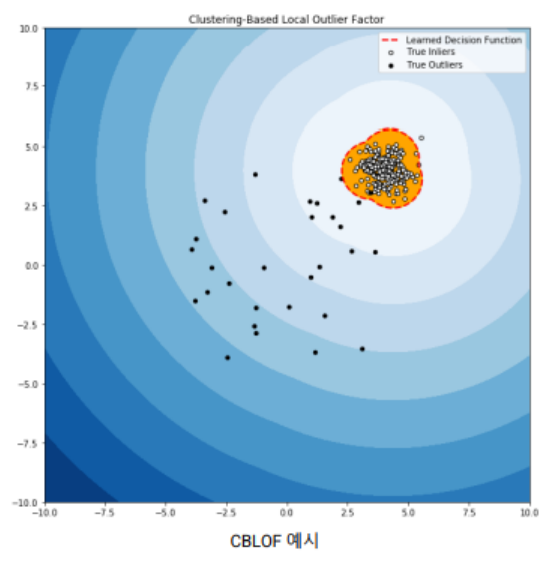
정상 값은 크거나 밀집된 클러스터에 속하고 이상 값은 작거나 희박한 클러스터에 속합니다.
- 관측값이 속한 군집의 크기나 밀도가 비정상인지 판단하는 기준
- FindCBLOF: 관측치가 속한 군집의 크기와 관측치와 해당 군집의 중심 사이의 거리를 반영하는 방법
통계적 방법
- 기본 원칙: 이상값은 가정된 확률 분포에서 나오지 않으므로 부분적으로 또는 완전히 범위를 벗어난 관측치입니다.
- 특이치는 확률 분포의 하단에서 발생하는 것으로 가정합니다.
- 테스트 통계를 기반으로 훈련된 모델에서 생성되지 않았을 가능성이 있는 관찰은 이상치로 간주됩니다.
- 파라메트릭 기법과 비파라메트릭 기법을 모두 사용할 수 있습니다.
1. 파라메트릭 기법
- 정규 분포 기반
- 최대 우도 추정을 통한 모수 추정
- 각 관측값과 추정 평균 사이의 거리가 이상값입니다.
- 그럽의 테스트
- 회귀 모델 기반
- 회귀 모델을 피팅한 후 이상치 값은 테스트 관찰의 잔차로 계산됩니다.
- 학습 데이터에 이상값이 있으면 영향을 받음
- 강력한 회귀를 통해 이상값을 정렬하고 동시에 찾을 수 있습니다.
- 혼합 파라메트릭 모델 기반
- 데이터에서 매개변수 분포를 혼합하는 모델 사용
- 정규값과 이상치에 대해 서로 다른 분포를 부여하거나, 정규값에 대해서만 혼합 분포를 부여한다.
2. 비모수 기법
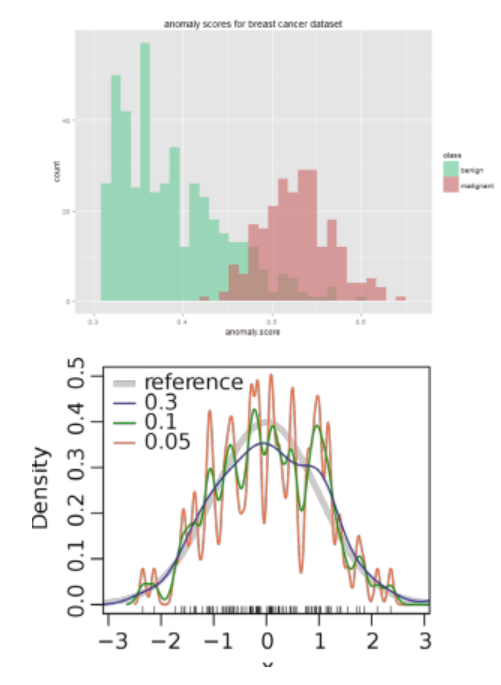
- 히스토그램 기반
- 훈련 데이터로 히스토그램을 생성한 후 검정 관찰값이 유의한 구간에 포함되면 정상, 그렇지 않으면 비정상으로 판단
- 이상값 점수는 때때로 관찰이 포함된 간격의 빈도를 기반으로 합니다.
- 데이터가 다변량인 경우 각 변수의 히스토그램에서 이상값 점수를 검색하고 합산하여 전체 이상값 점수를 얻습니다.
- 커널함수 기반 : 비모수적 밀도함수 추정기법, Parzen window
스펙트럼 기술
- 데이터의 대부분의 변동성을 설명하기 위해 근사화된 변수의 조합
- 데이터가 저차원 하위 공간으로 전송될 때 해당 공간에서 정상과 비정상 사이에 명확한 구분이 있다고 믿어집니다.
- 주요 구성 요소 분석
- 저차원 공간에 데이터를 투영할 때 데이터의 상관 구조를 만족하는 정상 객체는 낮은 투영 값을 가지며, 상관 구조를 벗어나는 이상 객체는 높은 값을 나타낸다.
- 고차원 데이터 처리에 적합
시계열 데이터의 이상 감지
- 상황별 이상은 시계열 데이터에서 종종 발견됩니다.
- 컨텍스트는 일반적으로 시간적 특성을 나타냅니다.
- 이상형
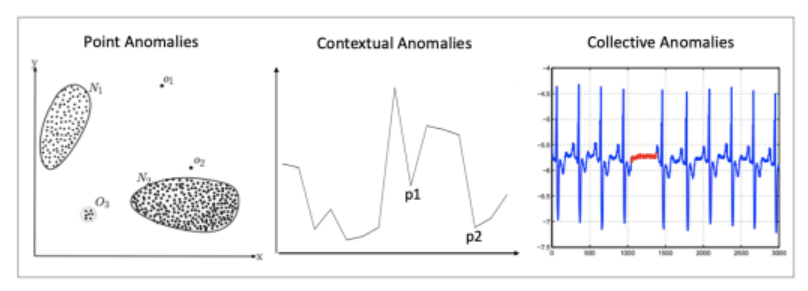
-
- 점 이상: 데이터의 다른 범주와 크게 다른 데이터의 개별 인스턴스입니다.
- Contextual anomalies: 인스턴스 자체가 다른 데이터의 값 범위를 벗어나지는 않지만 특정 컨텍스트에서 예외로 간주되는 경우.
- 집합적 변칙: 데이터 세트가 전체 데이터 세트와 다른 유형인 경우.
- 시계열 데이터에서 이상 징후를 감지할 때 전후 인스턴스와 컨텍스트를 함께 고려해야 합니다.
- 가산적 이상값: 단기간에 강력한 급증(예: 단기간에 웹사이트 사용자 수가 갑자기 증가)
- 시간적 변화: 이상값의 유형입니다. B. 웹사이트가 다운되고 사용자 수가 0이 될 때.
- 레벨 이동 또는 계절별 레벨 이동: 예를 들어 일부 전환 퍼널을 처리할 때 이상값은 변화를 일으키고 전환율을 낮춥니다.
- RNN, LSTM 등 시퀀스 데이터를 처리할 수 있는 알고리즘과 Autoencoder 등의 이상 탐지 알고리즘을 결합하여 사용
- RNN과 같은 네트워크는 단일 인스턴스 대신 시퀀스를 입력 값으로 사용할 수 있으므로 시간적 특성을 고려하여 이상값을 감지할 수 있습니다.
STL 분해
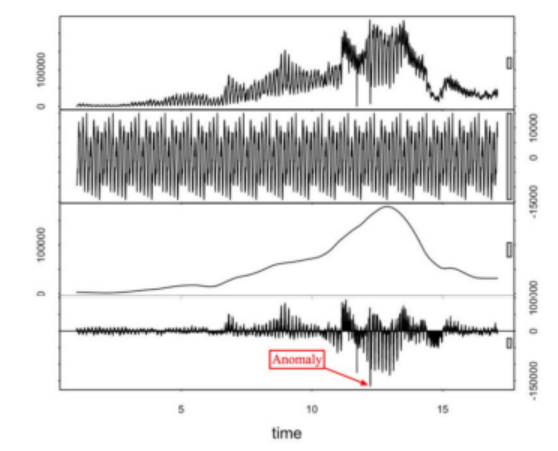
- STL: 황토를 기반으로 한 계절적 추세 분해
- 뢰스
* 지역 회귀- 각 대표점에 대한 회귀 피팅 후 모델을 생성하는 비선형 회귀 알고리즘
- 시계열 데이터는 계절, 추세 및 시차의 세 부분으로 나눌 수 있습니다.
- 간단하고 강력한
- 다양한 상황에 적용 가능하며 모든 이상치에 대한 직관적인 해석
- 가산 이상값을 감지하는 데 특히 좋습니다.
- 데이터의 특성이 빠르게 변할 때 제대로 작동하지 않음
SH ESD
- 계절 하이브리드 ESD(Extreme Studentized Deviate)
- STL로 계절성 및 추세 효과 제거
- MAD 및 Grubbs 테스트와 같은 강력한 메트릭이 사용됩니다.
- 평균 절대 편차(MAD)
* 중앙값에서 중앙값을 뺀 값의 중앙값- 표본 분산보다 이상값의 영향을 덜 받는 분산 측정
- Grubb 테스트(=ESD 테스트): 정규분포를 가정하여 단일 이상값을 찾는 방법
- 일반화된 ESD
* 다중 이상값을 가정한 테스트 방법- 정규성을 가정하기 때문에 먼저 정규성을 테스트해야 합니다.
- 계절성을 고려하지 않음 -> STL을 먼저 실행
자기회귀 통합 이동 평균(ARIMA)
- AR(자기 회귀) 모델 + MA(이동 평균) 모델.
- 고정 시계열 데이터의 가정
- 정상성: 평균과 분산이 시간에 따라 일정함을 의미합니다. 즉, 시계열 데이터의 속성이 시간에 따라 변하지 않음을 의미합니다.
- 고정 시계열 변환
- 분산이 일정하지 않은 경우: 로그 변환
- 추세와 계절성이 있는 경우: 첫 번째 차이로 고정되지 않은 경우 차별화, 반복 차이
- AR 모델: 이전의 관찰이 나중에 관찰에 영향을 미친다는 생각을 기반으로 합니다.
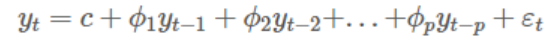
- MA 모델: 예측 오류를 사용하여 미래를 예측하는 모델
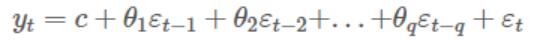
- ARIMA 모델: 위의 AR(p) 모델과 이산 d-order 데이터에 대한 MA(q) 모델을 결합한 모델
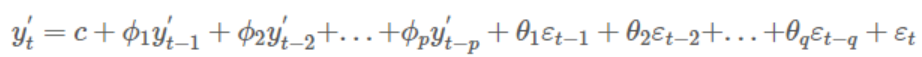
- 과거 포인트로 다음 포인트를 예측하기 위해 화이트 노이즈라는 랜덤 변수를 더해 예측을 생성하는 방식
- 이러한 예측 포인트는 다음 포인트를 예측하기 위해 자동회귀적으로 사용됩니다.
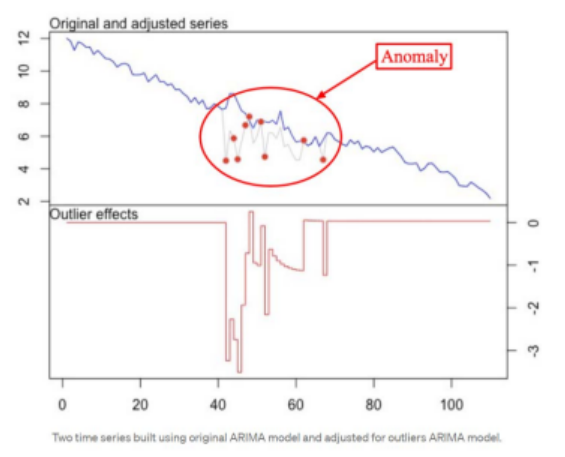
- 적합한 신호 세트를 생성하고 이를 원래 세트와 비교하여 이상값 감지
- 자동 회귀 차수(p), 차이 수(d) 및 예측 오차 계수(q)를 선택해야 합니다.
- 신호는 미분 후 정지 상태를 유지해야 합니다.
지수평활
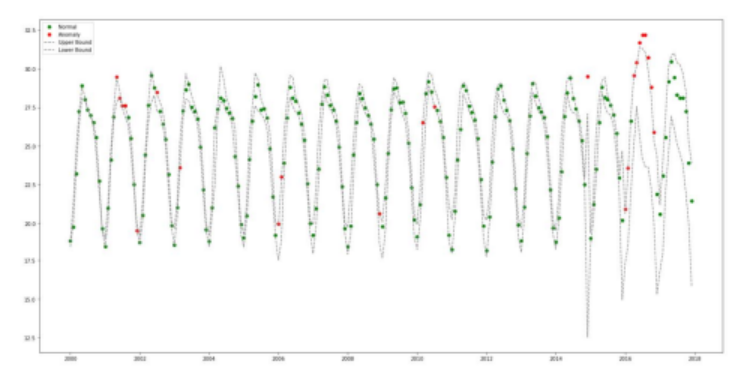
- ARIMA와 유사하게 추세, 수준 및 계절성을 사용하지만 현재 결과에 가중치를 추가하거나 줄일 수 있습니다.
- SES(Single Exponential Smoothing): 추세와 수준을 참조하십시오.
- Holt-Winters 모델: 추세, 수준 및 계절성을 함께 고려
- Brutlag 알고리즘은 신뢰 구간을 계산하여 정상 값과 비정상 값을 구분합니다.
분류 및 회귀 트리(CART)
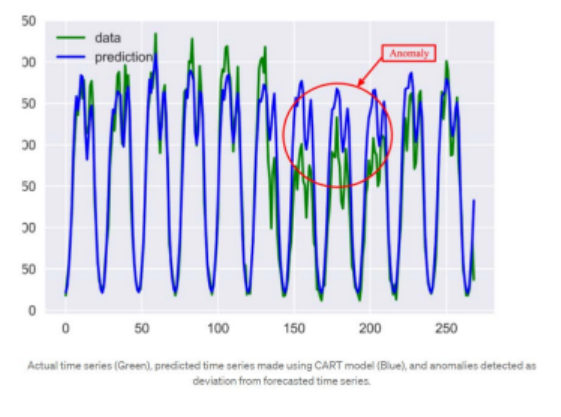
- 가장 널리 사용되는 결정 트리 알고리즘
- 가장 강력하고 효과적인 기계 학습 기술 중 하나
- 실제 데이터 차트와 예측 차트의 큰 편차를 이상값으로 감지
- Signal의 어떤 구조에도 연결되지 않음
- 학습을 위해 많은 특징 매개변수를 사용하여 보다 정교한 모델을 얻을 수 있습니다.
LSTM 기반 이상 탐지
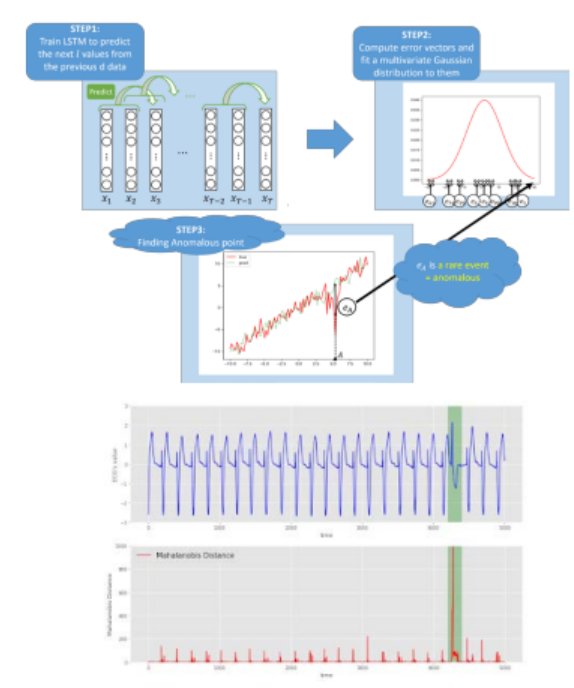
- 시계열 데이터의 과거 값을 사용하여 단계 직후에 값을 예측하도록 모델을 학습합니다.
- 오류 벡터를 계산하고 다변량 가우시안 분포를 오류 벡터에 맞춥니다.
- 오차가 가우스 분포의 끝에서 예측값과 실제값 사이에 있으면 이상값으로 간주됩니다.
- 우리는 Mahalanobis 거리를 사용하여 분포 내의 예측 및 오류에 대한 희소 집합을 나타냅니다.
LSTM 오토인코더
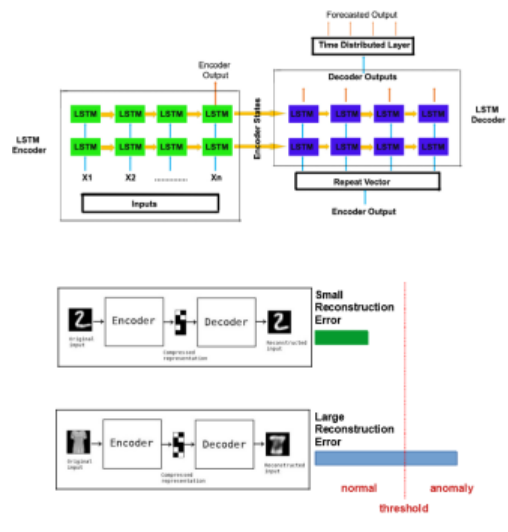
- RNN의 강점 중 하나는 과거 정보를 사용하여 현재 문제를 해결할 수 있다는 것입니다.
- LSTM은 주로 Vanishing Gradient 문제를 해결하는 데 사용됩니다.
- Autoencoder: 이상 데이터가 거의 없거나 전혀 없는 경우에도 적용 가능
- 기존 오토인코더는 시간 속성을 포함할 수 없으므로 LSTM 계층을 사용하여 오토인코더를 구성합니다.
- 이상값 데이터가 모델에 입력되면 재구성 오류가 매우 높습니다.
- 어차피 계산된 오차를 그대로 사용하면 오차 값은 보통 빠르게 증가할 수 있으므로 EWMA로 평활화한 후 사용한다.
- 동적 오류 임계값
- 임계값은 오류율로 계산되고 적용됩니다.
- 설정된 오류에 따라 임계값이 다를 수 있습니다.
- 일련의 오류를 기반으로 임계값을 계산하므로 편리하고 정확합니다.